
Methoden der Technologiefrühaufklärung
Anhand unterschiedlicher methodischer Ansätze werden mögliche zukünftige Entwicklungen und Trends in den unternehmensrelevanten Kontext gesetzt. Typisch sind daher beispielsweise die Entwicklung von Zukunftsszenarien, Technology Foresight und Technologieanalysen und die Bewertung von zukünftigen Technologien.
Schwerpunkte des Corporate Technology Foresight
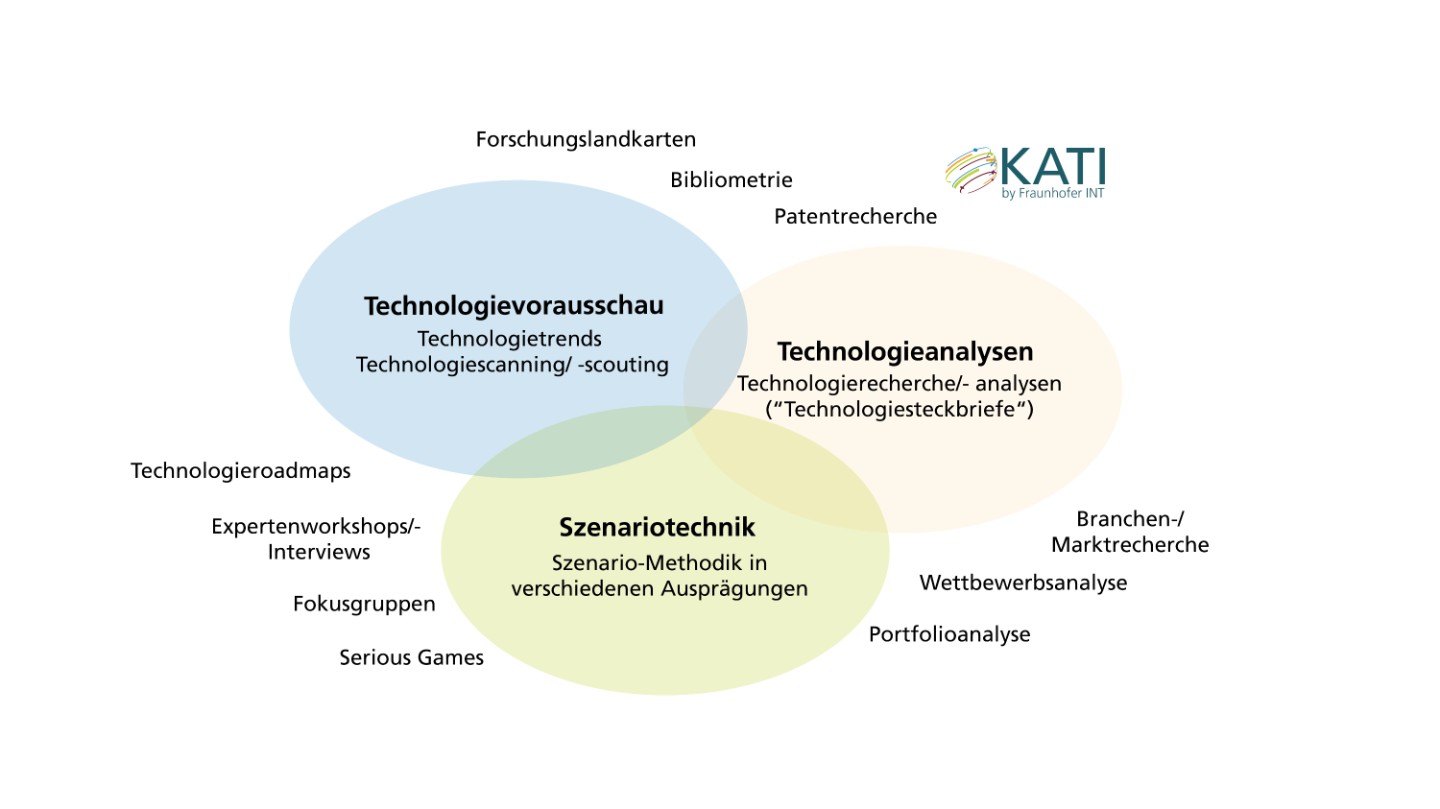
Das Fraunhofer-Institut für Naturwissenschaftlich-Technische Trendanalysen (INT) scannt die weltweite Technologielandschaft und analysiert auf dieser Basis technologische Entwicklungen. Die Technologielandschaft besteht seit 2017 im Web of Science mit mehr als 2.500.000 Publikationen. Das sind 48.000 Publikationen in der Woche, die ein Zukunftsforscher für ein vollständiges Bild lesen müsste.
Im Zentrum einer erfolgreichen Technologie-Anwendung steht der Mensch. In den Laboren von heute werden die Technologien von morgen entwickelt, aber welche davon sind wirklich relevant und können den Menschen bei seiner Arbeit oder im Alltag unterstützen? Mit einem neuen Gaming- und Simulationsansatz kommen unsere Wissenschaftler mit den Menschen ins Gespräch und finden so spielerisch heraus, worauf es der Gesellschaft ankommt. Das ist zum einen wichtig, um die richtige Forschungsstrategie zu erarbeiten und zum anderen aber auch um bedarfsgerechte Technologien zu entwickeln.
Assistenzsystem KATI unterstützt Forscher beim Lesen und Analysieren
Das System Knowledge Analytics for Technology and Innovation (KATI), ein Forschungsprojekt des Fraunhofer INT, ist ein IT- und datenbasiertes Assistenzsystem, welches die Wissenschaftlerinnen und Wissenschaftler bei ihren Technologievorausschau-Aktivitäten unter- stützt. KATI besteht aus einer modernen Datenbankarchitektur und beinhaltet derzeit die bibliographischen Daten von mehr als 59.000.000 wissenschaftlichen Publikationen mit interaktiven Visualisierungen und Analyse-Ergebnissen. Diese orientieren sich an typischen Fragestellungen der Technologievorausschau und betreffen konkret die Identifikation von Schlüsselpublikationen, Akteursanalysen und Technologieanalysen. Insbesondere die Fähigkeit mittels Data-Driven-Foresight neues Wissen zu generieren und zu visualisieren soll KATI bei Projektabschluss ein Alleinstellungsmerkmal verleihen.
Wissenschaftlich recherchieren mittels „Cognitive Computing“
Der Name KATI steht für Knowledge Analytics for Technology & Innovation. Das Projekt baut auf der inhaltlichen Kompetenz der Mitarbeiterinnen und Mitarbeiter aus der Abteilung Technologieanalysen und Strategische Planung insbesondere in der Technologiefrühaufklärung und Technologieanalyse auf. Ein weitere, wichtige Voraussetzung für das Vorhaben ist die methodische Kompetenz in den Bereichen der quantitativen Verfahren der Zukunftsforschung sowie der Informationsvisualisierung, die am Fraunhofer INT während der letzten Jahre erarbeitet wurde.
Ziel des Systems, welches im Rahmen dieses Forschungsvorhabens entwickelt wird, ist es, die Mitarbeiterinnen und Mitarbeitern an zahlreichen Stellen ihrer täglichen Arbeit zu unterstützen. Das betrifft zunächst vor allem die Recherche in wissenschaftlichen Datenbanken. Das System zielt darauf ab, die benötigte Zeit für die Suche nach relevanten Publikationen deutlich zu verringern, um somit den Wissenschaftlerinnen und Wissenschaftlern mehr Zeit für die inhaltliche Auseinandersetzung mit einem Thema zu geben. Diese sollen zusätzlich dadurch unterstützt werden, dass wichtige Analysen, die heute noch sehr zeitaufwendig sind, beschleunigt und automatisiert werden. Schließlich soll das System darüber hinaus völlig neue Analysemöglichkeiten eröffnen, die derzeit aktiv entwickelt werden.
„Cognitive Computing“ für die Technologiefrühaufklärung
Im fertigen System sollen auch Verfahren des „Cognitive Computing“ zum Einsatz kommen. Darunter versteht man den Versuch, mittels Software die menschliche Erkenntnisfähigkeit, die sogenannte Kognition, nachzuahmen. Ergänzt werden diese durch Algorithmen aus den Bereichen Data-Mining, maschinelles Lernen und Big Data. Diese werden eingesetzt, um große Textmengen zu clustern, darin Muster zu erkennen, diese zu klassifizieren und Abweichungen – sogenannte Anomalien – zu detektieren.
Quelle: Fraunhofer-Institut für Naturwissenschaftlich-Technische Trendanalysen (INT)
https://www.int.fraunhofer.de/